
Small lessons I learned at Monzo 🚀
I’m a Platform Engineer at Monzo since August 2018 and a recent conversation made me think of all the things I’ve learned over the last 4 short months. I wanted to share about how we work and what I’ve learned here.
Briefly, the Monzo banking platform is roughly 820 micro services on Kubernetes. Some of them run a handful of replicas while others run into over 100. As of writing, we run over 6200 pods in about 350 nodes. Except for a small set of physical servers required to connect to various payment networks, everything else runs on AWS. Almost all data is stored in Cassandra with a little bit of Elastic Search. Kafka and NSQ act as message brokers. Prometheus and Grafana offer extensive monitoring. See the blog Building a Modern Bank Backend for more details.
The platform team is split into 2 squads, one that concentrates on the infrastructure and reliability while the other takes care of engineering effectiveness. I’m part of the former and that in practice means we provision, scale and monitor the infrastructure required to run the bank and continuously make improvements to support a rapidly evolving product and the roughly 100 engineers working on it.
Monzo is the largest company project I’ve ever worked on in terms of users,
engineers, lines of code and scale. A ton of the software we use was new to me
and I had lots of fun (and a fair share of anxiety) learning them all as quickly
as possible during the first 2 or 3 months. I’ve learned a lot about how some
specific software works like Kubernetes, Cassandra and Wireguard but the soft
skills or life lessons were far more valuable. When I look back, the relief that
not all software engineering jobs in the world suck makes me so much happier 🙏.
1. Culture can make an enormous difference 🏦
We have a diverse workforce building something together that they (and their moms) would love to use and would be proud of. I worked on developer tools at a previous job and every single engineer on the project I knew of passionately hated the project and never used any of it. It is impossible to be a productive engineer and look ahead while you are soaked in so much toxicity. I see employees excited about what we can already do and the mountain of possibilities ahead of us. Conversations change from bitching about management to knowledge sharing and cool feature updates over lunch. You go back to your desk happy. It is a very powerful feedback cycle.
We acquired a million customers in just about 3 years while maintaining a NPS score over +80. We had an incredible crowdfunding round raising 20M£ in just under 3hrs which shows how much customers believe in the product. I think behind every milestone, there are a lot of happy employees loving what they do. This manifests as proactively sending customers new cards even before they realise that British Airways leaked their information or the whole company joining hands to answer support queries when the wait times got high.
2. Scaling teams and code 👩💻
Almost all of the application code is in Go and each micro service is a top level folder in a monorepo built with a few shared libraries and tools and works incredibly well for us. New engineers can start with a service without having to learn about the whole platform. Experiments and old features and get cleaned up when it’s not needed anymore because its usually just deleting a service and a few callers into it. Service deployments are independent of each other and usually, there are more than 50 deployments every day.
I learned how valuable good tooling is. A small engineering effectiveness team can make the lives of so many engineers so much better when the tools to deploy, monitor, check logs etc “just work”. If you can deploy and rollback safely with just one single command, it encourages engineers to deploy small and often making the whole process a lot safer. This improves confidence in doing things and helps engineers iterate so much faster. I’ve wasted days in the past building completely unrelated downstream projects after changing shared Jenkins libraries. Never again.
💡 Invest in tooling.
3. A good orientation matters 🧭
Please don’t link your next new engineer to a git repo and README.md and expect them to find everything on their own. Every company have unique ways of doing things, the context that is not written down anywhere and broken processes that everyone is not aware of.
A “buddy” 👫 for the first week or so just to show you how everything works can be a huge bonus 💪. I started at Monzo looking into how we run our database cluster and mistakes there would have been costly. I cannot overstate how much having someone to ask dumb questions helped. Come back @spikelindsey!
4. Scaling infrastructure 💾
I’ve never been in a platform/infrastructure/devops role before and I had to start at level 0. The most complicated thing I had done with AWS before Monzo was to setup a VM for a tiny web application. It took me quite some time to get used to the nuances of Terraform to manage a large production fleet. It took a while to clean up some of the cruft left behind, but we are very close to the state of the entire infrastructure described in Terraform and Puppet and “Infrastructure as code” is taken for granted at Monzo. Being able to raise a Terraform PR and discuss it instead of clicking random buttons in the EC2 UI 🕵️♀️ made it so much easier for a newbie like me to get work done.
Not rocket science 🚀 but you should switch to a tool that lets you describe infrastructure as code asap.
5. Technical debt 🕸
I learned that at the heart of it, technical debt is a cultural problem than a technical problem.
When I started, the puppet code we used for configuring infrastructure at Monzo was really old and crufty, but now we are actually spending time and effort to clean it up. I was mad about not version controlling our Grafana dashboards and not syncing them across prod and staging environments - I fixed it last week. Some of our critical infrastructure diverged from the version controlled config, we fixed it too. We needed centralised logging and distributed tracing, both got shipped in the last 3 months. The operations around Cassandra improved massively over the last 6 or 7 months. And several other projects that I’m not aware of are getting fixed right now.
There is cruft and mess in every large software out there but they differ in how people deal with it. Unless you have a culture of fixing things up once in a while, eventually it compounds so much to make it hell. Under some conditions, technical debt is a useful tool but you need to be careful about it. It’s a thin line. The next time I come across something badly broken at Monzo, I know I can eventually get it fixed and won’t have to live with it forever. Building that culture is hard, but would pay off massively in the long run.
6. Monitoring 📈
Good infrastructure starts with good monitoring and alerts. I’ve never worked with any sort of serious monitoring before and I do not want to go back. I learned Prometheus and Grafana at Monzo and they are both really good at what they do and I developed some sort of fascination for pretty informative charts. Each graph is a story. Here are some random ones I liked:
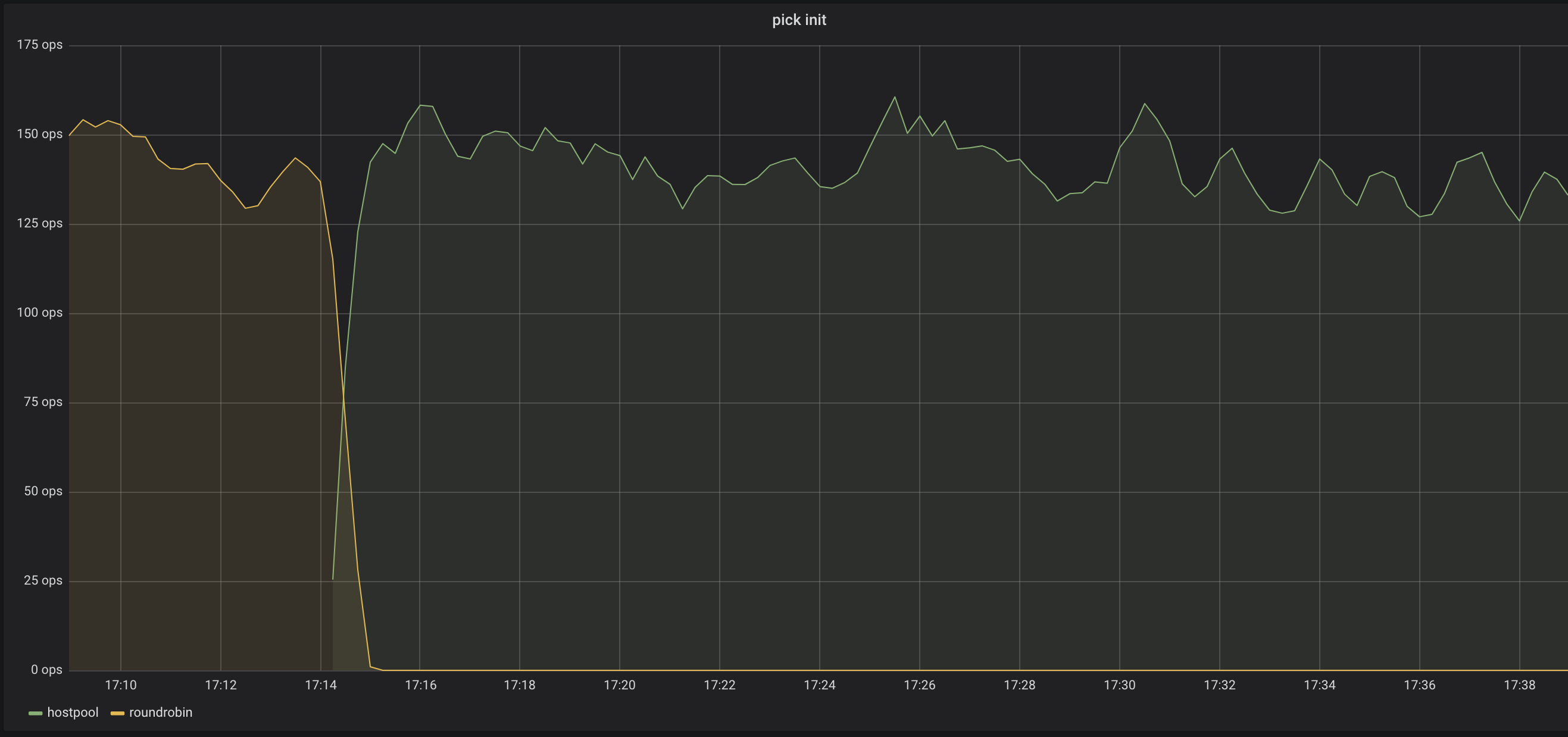
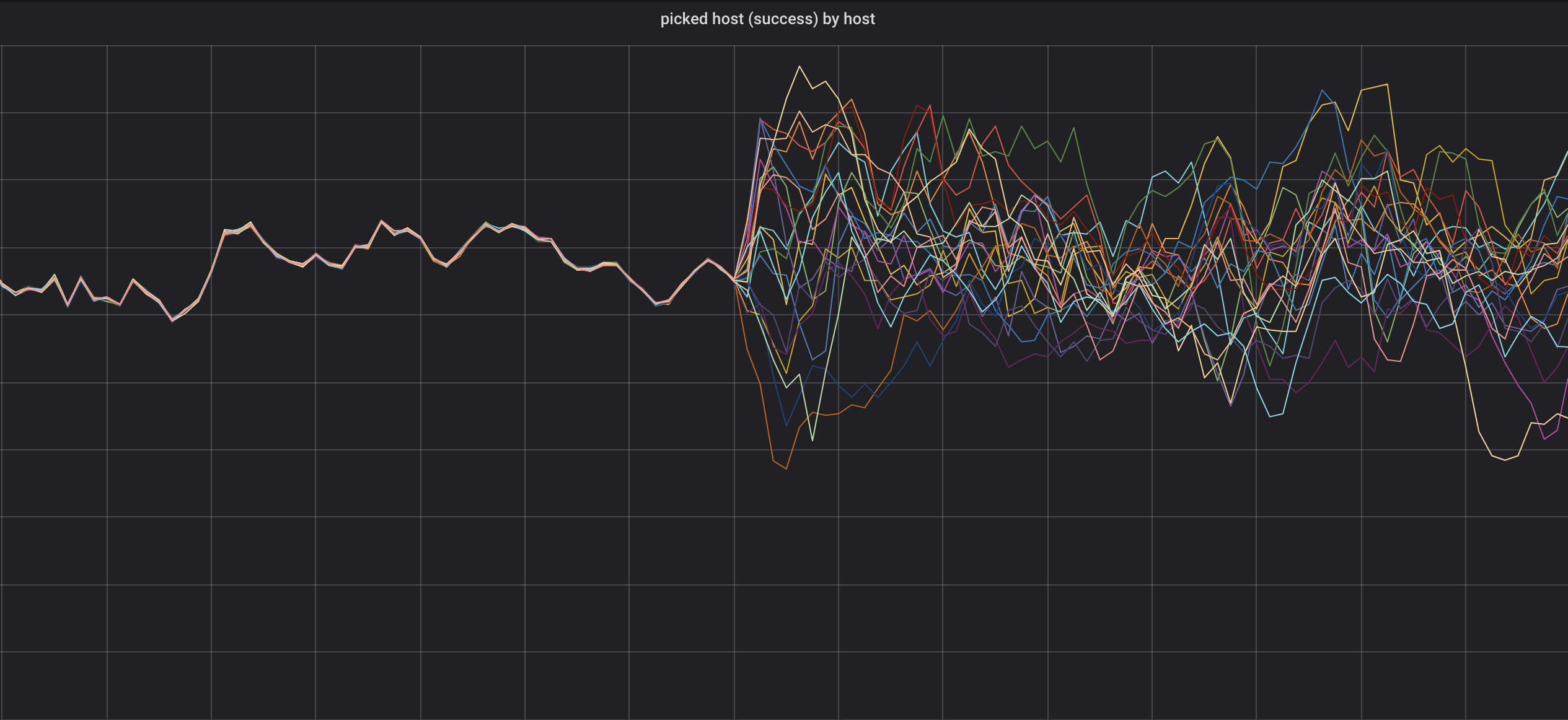
We changed the way Kubernetes pods connect to the database and you can see in the first graph how one policy changes to the other cleanly and in the second graph how the cluster picks DB nodes more intelligently considering several factors rather than a simple round robin. This would be impossible to understand from just logs.
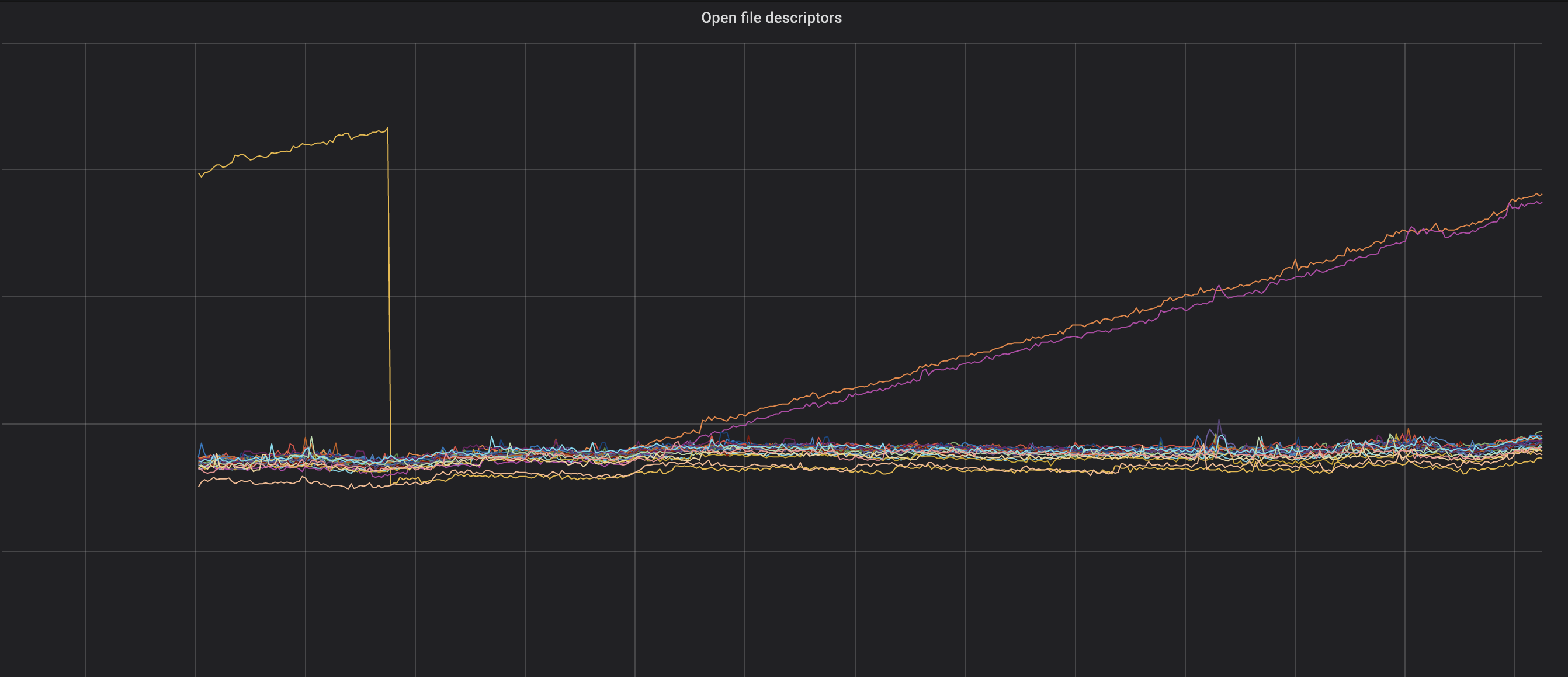
This graph on open file descriptors helped us track down a leak in the Prometheus JMX exporter and fix it.
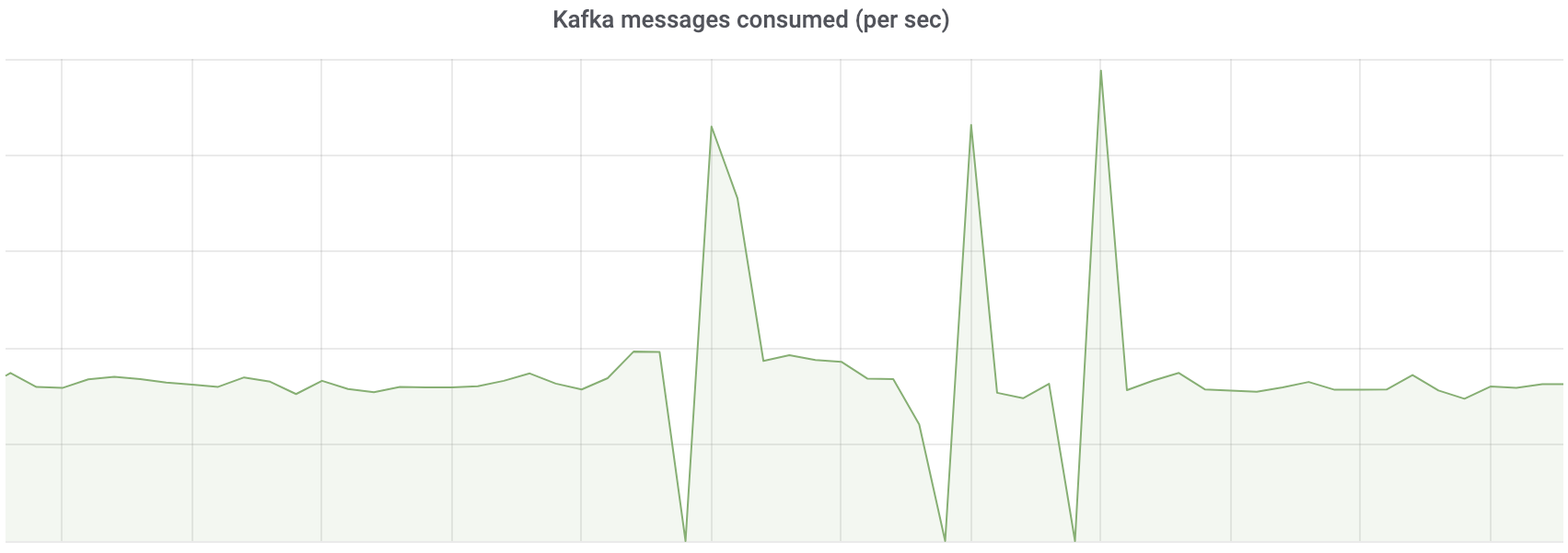
This one shows how Kafka acts as a nice message buffering queue and lets us restart databases for a short time with no visible downtime.
And a few more.
-
We have a strong feedback culture and people do it frequently. It helps you learn about the problems early and act on it.
-
I went to an actual data centre and learned a little bit about how the physical infrastructure works. Fascinating.
-
Making processes inclusive for remote workers forces us to write down a lot more documentation which is awesome.
-
Cassandra is a really really complicated piece of software to understand, use and operate. I’m having a love hate relationship with it right now. More on it later.
-
Go works really well for Monzo but I’m not a fan of it. Almost everyone else seems to love it. I’m extremely biased when it comes to programming languages because I spent most of my free time thinking about Haskell.
It a been a long one with lessons, rants and stories. Let me know what you think. Thanks a lot to @indradhanush92, @aishpant, @vimalk78 and @rusrushal13 for proof reading early versions of this draft.